
词向量,英文名叫Word Embedding,在自然语言处理中,用于抽取语言模型中的特征,简单来说,就是把单词用一个向量来表示。最著名的Word Embedding模型应该是托马斯·米科洛夫(Tomas Mikolov)在Google带领的研究团队创造的Word2vec。
词向量的训练原理就是为了构建一个语言模型,我们假定一个词的出现概率是由它的上下问来决定的,那么我们找来很多的语素来训练这个模型,也就是通过上下文来预测某个词语出现的概率。
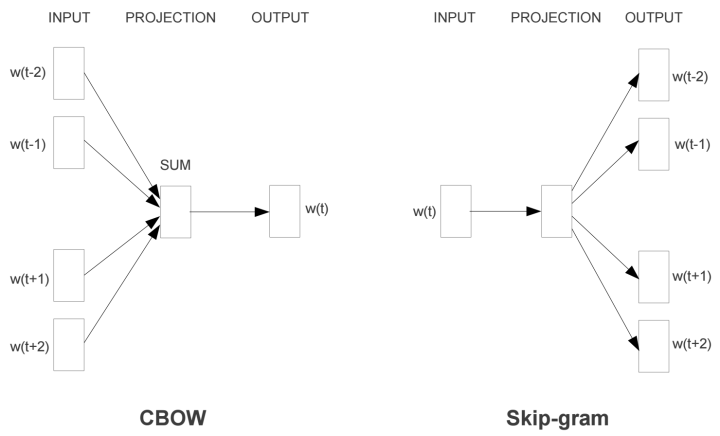
如上图所示,词嵌入向量的训练主要有两种模式:
- 连续词袋 CBOW, 在这个方法中,我们用出现在该单词的上下文的词来预测该单词出现的概率,如上图就是该单词的前两个和后两个。然后我们可以扫描全部的训练语素(所有的句子),对于每一次出现的词都找到对于的上下文的4个词,这样我们就可以构建一个训练集合来训练词向量了。
- Skip-Gram和CBOW正好相反,它是用该单词来预测前后的4个上下文的单词。注意这里和上面的4个都是例子,你可以选择上下文的长度。
那么训练出来的词向量它的含义是什么呢?
词向量是该单词映射到一个n维空间的表示,首先,所有的单词只有在表示为数学上的向量后在能参与神经网络的运算,其次,单词在空间中的位置反映了词与词之间的关系,距离相近的词可能意味着它们有相近的含义,或者经常一出现。
用神经网络构建语言模型的时候,Embedding常常是作为第一个层出现的,它就是从文本中提取数字化的特征。那么我们今天就看看如何利用TensorflowJS在训练一个词向量嵌入模型吧。
倒入文本
首先倒入我的文本,这里我的文本很简单,你可以替换任何你想要训练的文本
const sentence = "Mary and Samantha arrived at the bus station early but waited until noon for the bus.";
抽取单词和编码
然后,抽取文本中所有的单词序列,在自然语言处理中,Tokenize是意味着把文本变成序列,我这个例子中的单词的抽取用了很简单的regular expression,实际的应用中,你可以使用不同的自然语言处理库提供的Tokenize方法。TensorflowJS中并没有提供Tokenize的方法。(Tensorflow 中由提供 )
const tokenize = words => { return words.match(/[^\s\.]+/g);}// tokenizeconst tokens = tokenize(sentence); 单词序列如下:
["Mary", "and", "Samantha", "arrived", "at", "the", "bus", "station", "early", "but", "waited", "until", "noon", "for", "the", "bus"]
下一步我们要对所有的单词编码,也就是用数字来表示每一个单词
const encode = tokens => { let encoding_map = {}; let decoding_map = {}; let index = 0; tokens.map( token => { if( !encoding_map.hasOwnProperty(token) ) { const pair = {}; const unpair = {}; pair[token] = index; unpair[index] = token; encoding_map = {...encoding_map, ...pair}; decoding_map = {...decoding_map, ...unpair}; index++; } }) return { map: encoding_map, count: index, encode: function(word) { return encoding_map[word]; }, decode: function(index) { return decoding_map[index]; } };}const encoding = encode(tokens);const vocab_size = encoding.count; 编码的方式很简单,我们统计每一个出现的单词,然后给每一个单词一个对应的数字。我们使用了两个map,一个存放从单词到数字索引的映射,另一个存放相反的从索引到单词的映射。这个例子中,一种出现了14个单词,那么索引的数字就是从0到13。
准备训练数据
下一步,我们来准备训练数据:
const to_one_hot = (index, size) => { return tf.oneHot(index, size);} // training dataconst data = [];const window_size = 2 + 1;for ( let i = 0; i < tokens.length; i ++ ) { const token = tokens[i]; for ( let j = i - window_size; j < i + window_size; j ++) { if ( j >= 0 && j !=i && j < tokens.length) { data.push( [ token, tokens[j]] ) } }}const x_train_data = [];const y_train_data = [];data.map( pair => { x = to_one_hot(encoding.encode(pair[0]), vocab_size); y = to_one_hot(encoding.encode(pair[1]), vocab_size); x_train_data.push(x); y_train_data.push(y);}) const x_train = tf.stack(x_train_data);const y_train = tf.stack(y_train_data);console.log(x_train.shape);console.log(y_train.shape); one_hot encoding是一种常用的编码方式,例如,对于索引为2的单词,它的one_hot encoding 就是[0,0,1 .... 0], 就是索引位是1其它都是0 的向量,向量的长度和所有单词的数量相等。这里我们定义的上下文滑动窗口的大小为2,对于每一个词,找到它的前后出现的4个单词构成4对,用该词作为训练的输入,上下文的四个词作为目标。(注意在文首尾出的词上下文不足四个)
0: (2) ["Mary", "and"]1: (2) ["Mary", "Samantha"]2: (2) ["and", "Mary"]3: (2) ["and", "Samantha"]4: (2) ["and", "arrived"]5: (2) ["Samantha", "Mary"]6: (2) ["Samantha", "and"]7: (2) ["Samantha", "arrived"]8: (2) ["Samantha", "at"]9: (2) ["arrived", "Mary"]10: (2) ["arrived", "and"]... ...
训练集合如上图所示,第一个词是训练的输入,第二次的训练的目标。我们这里采用的方法类似Skip-Gram,因为上下文是预测对象。
模型构建和训练
训练集合准备好,就可以用开始构建模型了。
const build_model = (input_size,output_size) => { const model = tf.sequential(); model.add(tf.layers.dense({ units: 2, inputShape: output_size, name:'embedding' })); model.add(tf.layers.dense( {units: output_size, kernelInitializer: 'varianceScaling', activation: 'softmax'})); return model;}const model = build_model(vocab_size, vocab_size); model.compile({ optimizer: tf.train.adam(), loss: tf.losses.softmaxCrossEntropy, metrics: ['accuracy'],}); 我们的模型很简单,是一个两层的神经网络,第一层就是我们要训练的嵌入层,第二层是一个激活函数为Softmax的Dense层。因为我们的目标是预测究竟是哪一个单词,其实就是一个分类问题。这里要注意得是我是用的嵌入层的unit是2,也就是说训练的向量的长度是2,实际用户可以选择任何长度的词向量空间,这里我用2是为了便于下面的词向量的可视化,省去了降维的操作。
训练的过程也很简单:
const batchSize = 16;const epochs = 500;model.fit(x_train, y_train, { batchSize, epochs, shuffle: true,}); 可视化词向量
训练完成后,我们可以利用该模型的embeding层来生成每一个单词的嵌入向量。然后在二维空间中展示。
// visualize embedding layerconst embedding_layer = model.getLayer('embedding');const vis_model = tf.sequential();vis_model.add(embedding_layer);const vis_result = vis_model.predict(predict_inputs).arraySync();console.log(vis_result);const viz_data = [];for ( let i = 0; i < vocab_size; i ++ ) { const word = encoding.decode(i); const pos = vis_result[i]; console.log(word,pos); viz_data.push( { label:word, x:pos[0], y :pos[1]});}const chart = new G2.Chart({ container: 'chart', width: 600, height: 600});chart.source(viz_data);chart.point().position('x*y').label('label');chart.render(); 生成的词向量的例子如下:
"Mary" [-0.04273216053843498, -0.18541619181632996]"and" [0.09561611711978912, -0.29422900080680847]"Samantha" [0.08887559175491333, 0.019271137192845345]"arrived" [-0.47705259919166565, -0.024428391829133034]
可视化关系如下图:
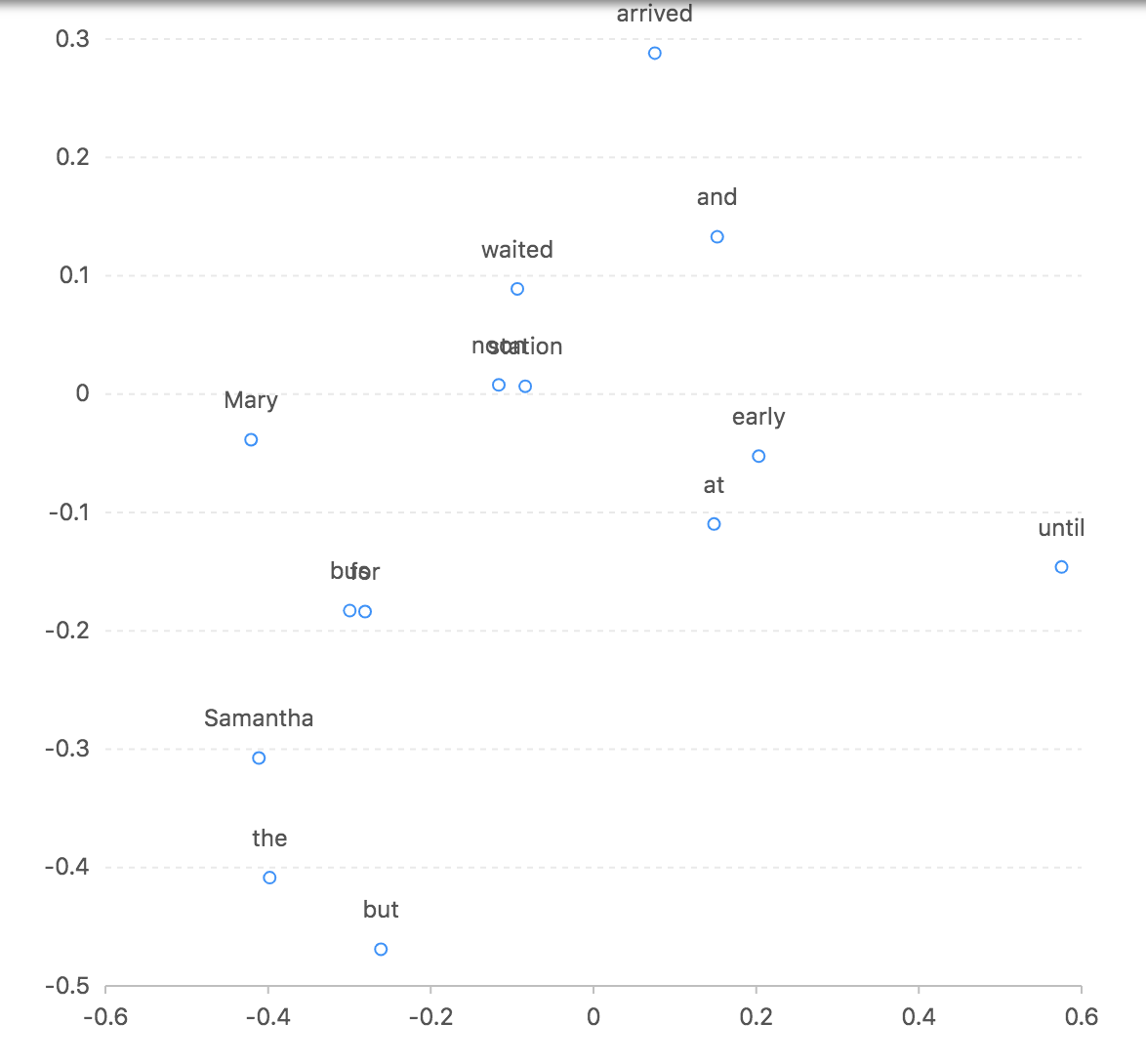
总结
词向量嵌入常常是自然语言处理的第一步操作,用于提取文本特征。我们演示了如何训练一个模型来构建词向量。当然实际操作中,你可以直接使用 来构建你的文本模型,本文是为了演示词向量的基本原理。代码参见